Harmonic minor scale
| Key | C | C# | Db | D | D# | Eb | E | E# | Fb | F | F# | Gb | G | G# | Ab | A | A# | Bb | B | B# | Cb |
|---|
Structure
A harmonic minor scale in a given key is similar to the Natural minor scale in the same key, except that the 7th note is raised by 1 half-tone / semitone to arrive at the harmonic minor scale.
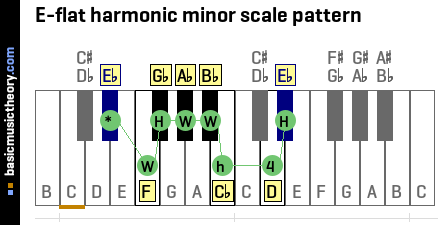
The harmonic minor scale uses the W-H-W-W-H-W½-H note counting pattern to identify the scale note positions.
The first note in the diagram below (*) is the tonic note, from which the counting pattern begins.
To count up a Whole tone, count up by two physical piano keys, either white or black.
To count up a Half-tone (semitone), count up from the last note up by one physical piano key, either white or black.
To count up a W½ tone (whole-tone and a half), count up from the last note by 3 half-tones / semitones - shown as 3 in the piano diagram below.
So in the example below, we are interested in the harmonic minor scale in the key of E-flat.
No matter which key name (or color - black / white) a major scale starts on, the same pattern above is used.
The 8th and final note in the diagram is the octave note, named the same as the tonic note, and is the note where the scale and tone / half-tone pattern rule starts repeating all the way up the piano keyboard.
To understand the frequency relationship between a tonic and its octave note, have a look at the Chromatic scale overview.
Examples
The example below, Eb harmonic minor scale, uses the key of E-flat.
The All harmonic minor scales page contains piano diagrams and key signatures for all harmonic minor scales.